矩阵分解算法——协同过滤的进化
协同过滤的问题
- 推荐结果的头部效应明显,处理稀疏向量的能力弱:
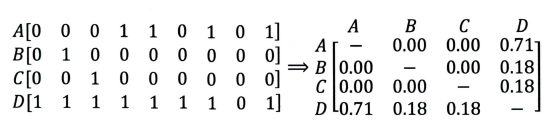 如上图所示,横坐标(A,B,C,D)表示物品,纵坐标表示用户评价。物品A, B, C彼此间相似度为0,且均与物品D有很大的相似度,但这很可能不是由于物品本身的相似度导致的。A, B, C相似度小可能由于A, B, C为非常冷门的物品,其特征向量非常稀疏,D则反之。这揭示了协同过滤难以处理稀疏向量的问题。
如上图所示,横坐标(A,B,C,D)表示物品,纵坐标表示用户评价。物品A, B, C彼此间相似度为0,且均与物品D有很大的相似度,但这很可能不是由于物品本身的相似度导致的。A, B, C相似度小可能由于A, B, C为非常冷门的物品,其特征向量非常稀疏,D则反之。这揭示了协同过滤难以处理稀疏向量的问题。 - 仅利用物品与用户的交互信息,无法引入其他物品特征及用户特征。
矩阵分解算法的原理
- 为每一个用户和物品生成一个隐向量(比如$\mathbb{R}^2$上的一个二位坐标向量),将距离用户相近的物品推给用户,这一向量通过分解共现矩阵实现: 其中$R$为共现矩阵,$U$为用户矩阵,$V$为物品矩阵;$m$为用户数量,$n$为物品数量,$k$是隐向量的维度。$k$决定了隐向量表达能力的强弱:$k$越大,泛化程度越低,越容易过拟合;反之相反。
- 基于用户矩阵$U$和物品矩阵$V$,可以预估用户u对物品i的评分:
矩阵分解的求解过程
主要包括三种分解方式:特征值分解,奇异值分解,梯度下降。
- 特征值分解
只能用于方阵,不适用。 - 奇异值分解(SVD),核心是保留前k个奇异值:其中$U$,$V$分别为正交矩阵,$\Sigma_{m\times n} = \rm diag\{\sigma_1,\sigma_2, \cdots,\sigma_\ell, 0, \cdots, 0\}$,$\sigma_1\geqslant\sigma_2\geqslant\cdots\geqslant\sigma_\ell>0$。取再令得到$R$的一个(近似)分解:奇异值分解的弊端:
(1). 不适合处理稀疏的共现矩阵;
(2). SVD的时间复杂度$\mathcal{O}(mn^2)$
所以也不适用。 梯度下降
寻找最佳的分解转化为优化问题:进一步,可以加入正则化项:
共$(mk+nk)$个变量需要优化。
对$p_u$求偏导:
采用随机梯度下降(随机抽取一个用户,$m=1$),对$p_u$更新:
同理对$q_i$更新
其中$\gamma$为学习率。
梯度下降到迭代次数超过阈值或损失低于阈值时结束。
消除用户相物品打分的偏差(?)
分别训练$p$,$q$,$b$,$\mu$。
矩阵分解的有点和局限性
- 泛化能力强;
- 空间复杂度低,不需要储存共现矩阵$R$,只需要储存$U$和$V$;
- 更好的扩展性,便于与其他方法结合。
逻辑回归——融合多种特征的推荐模型
逻辑回归能够综合利用用户、物品、上下文等多种不同的特征,生成较为”全面”的推荐结果。逻辑回归将推荐问题看成一个分类问题(点击率(Click Through Rate,CTR)预估问题。),通过预测正样本的概率对物品进行排序。
基于逻辑回归模型的推荐流程
- 构造特征向量;
- 训练模型;
- 对不同的物品,预估点击的概率;
- 按照点击概率排序,推荐点击概率靠前的。
逻辑回归模型的数学形式(略)
逻辑回归的优势
- 数学上的支撑:CTR模型,因变量表示点击与否,服从两点分布;
- 可解释性强(如权重的含义)
- 工程化需要
逻辑回归的局限性
表达能力不强,无法进行特征交叉、特征筛选等一系列较为”高级”的操作,因此不可避免地造成信息的损失。